
Чувства, музыка, машина
Чувства, музыка, машина это серия сгенерированных картинок при помощи обученной нейросети Stable Diffusion XL.
Я обучала нейросеть своим работам за последние три года. Долго думала над концепцией в итоге пришла к тому, что хочу совместить два своих любимых занятия в этом проекте: рисование и музыку. Стало интересно как будет работать тандем чувственного человеческого и машинного бесчувственного.
Любопытно было, как нейросеть, используя мой стиль рисования, интерпретирует названия моих любимых песен.
В промпте также прописывала чувства, которые вызывала каждая из песен.
Некоторые из моих работ, которые использовались в обучении


Так как я рисую преимущественно людей, большая часть работ, по которым училась нейросеть была без проработанных фонов. Из-за этого в последствии возникали некоторые трудности с генерацией картинок. К этому нюансу вернемся немного позже.
Пробы
Сначала я решила посмотреть какие картинки получаются в принципе при генерации с помощью этой машины. Задавала какие-то односложные промпты без уточнений.
Изображение, сгенерированное нейросетью
В целом нейросеть уловила моменты моего стиля. где-то небрежные мазки и лайн, плоские заливки. Цветовые решения так же похожи на картинки, которые были приложены для обучения.
Изображение, сгенерированное нейросетью
Изображение, сгенерированное нейросетью
Абстрактные сюжеты
Я решила посмотреть, на что будет делать уклон генерация, если я буду задавать размытые описания с акцентами на эмоциональное состояние: радость, гнев, печаль, другие. Добавляла в некоторых случая ассоциативные уточнения, например, острый к гневу или круглый к счастью. В некоторых случаях получить, нечто абстрактное удалась на ура, в других же генерация стала вырисовывать какие-то человекоподобные элементы.





Изображения, сгенерированное нейросетью
Пейзажи
С пейзажами ситуация обстояла сложнее. При генерации так и всплывали образы людей, очень часто приходилось прописывать дважды БЕЗ ЛЮДЕЙ. В таком случае получалось сгенерировать изображение пейзажа.







Изображение, сгенерированное нейросетью
Предметы
Отдельные изображения предметов выходили прикольными, но еще меньше были похожи, на мою рисовку. Опять же, думаю, что проблема в первоисточнике с моими рисунками людей.







Изображения, сгенерированное нейросетью
Забавное изображение наушников с глазками получилось, хотя в промпте я написала только слово «наушники». Круто, что нейросеть подметила мой прикол добавлять всему глазки.
Изображение, сгенерированное нейросетью
В некоторых генерациях так и не получилось избавиться от наличия человеческих фигур.




Изображения, сгенерированное нейросетью
Животные
Некоторые отдельные изображения животных: собака, лошадь и кот.
Изображение, сгенерированное нейросетью
Изображение, сгенерированное нейросетью
Изображение, сгенерированное нейросетью
Люди
После всех проб я убедилась, что все же люди получаются интереснее всего, поэкспериментировала с генерацией людей еще немного.
Изображение, сгенерированное нейросетью
Изображение, сгенерированное нейросетью
Изображение, сгенерированное нейросетью
Далее я приступила к генерации картинок, используя исключительно название различных песен.
Изображение, сгенерированное нейросетью
Изображение, сгенерированное нейросетью
Изображение, сгенерированное нейросетью
Сюжеты получались слишком абстрактными и далекими от сюжета песен и моего чувственного восприятия. Я думала, думала и пришла к решению давать размытые описания в промптах плюс к названию песни. От этого нейросеть генерировала более близкие к настроению песен изображения, при том «полет фантазии» для нейросети оставался доступным. Случались очень неожиданные и интригующие сюжеты, далекие от идеально вылизанной картинки, но это меня и радовало.
Я дополняла промпты размытыми определениями такими как: энергичная, агрессивная, веселая, так далее. Иногда добавляла слова дополняющие настроение песни.
Сгенерированные изображения до (слева) и после (справа) уточнения промпта.


Изображения, сгенерированное нейросетью (песня: Snake Dance — March Violets)


Изображения, сгенерированное нейросетью (песня: Sorry for Party Rocking — LMFAO)


Изображения, сгенерированное нейросетью (песня: Minus — ohGr)


Изображения, сгенерированное нейросетью (песня: Ghost Train — Gorillas)


Изображения, сгенерированное нейросетью (песня: The Night — The Moody Blues)


Изображения, сгенерированное нейросетью (песня: Just Another Day — OINGO BOINGO)


Изображения, сгенерированное нейросетью (песня: Faust — Gorillas)


Изображения, сгенерированное нейросетью (песня: Heavy Games — Portugal. The Man)


Изображения, сгенерированное нейросетью (песня: Old Heroes Young Villains — Rabbit Junk)


Изображения, сгенерированное нейросетью (песня: The Mummers' Dance — Loreena McKennitt)


Изображения, сгенерированное нейросетью (песня: Run! — Valorant, Odertari, Lay Bankz)
После уточнения картинки стали более интересными наполненными сюжетно. Довольно любопытный опыт получился. Мое чувственное и механическое нейроночное сошлись в одном и создали необычные интересные изображения на первый взгляд, ничего не имеющее с первоисточником (названиями песен) и при том по настроению отдалено связанные с их названиями, да еще и в чем-то схожем по стилю с моими рисунками. Как инструмент генерация картинок штука забавная.
Ноутбук с кодом для обучения и генерации
Ход работы
Скриншот из Google Collab
Сначала установила основные библиотеки. Затем установила diffusers прямо из репозитория GitHub. Скачала скрипт для обучения Dreambooth c Lora для SDXL (Stable Diffusion XL).
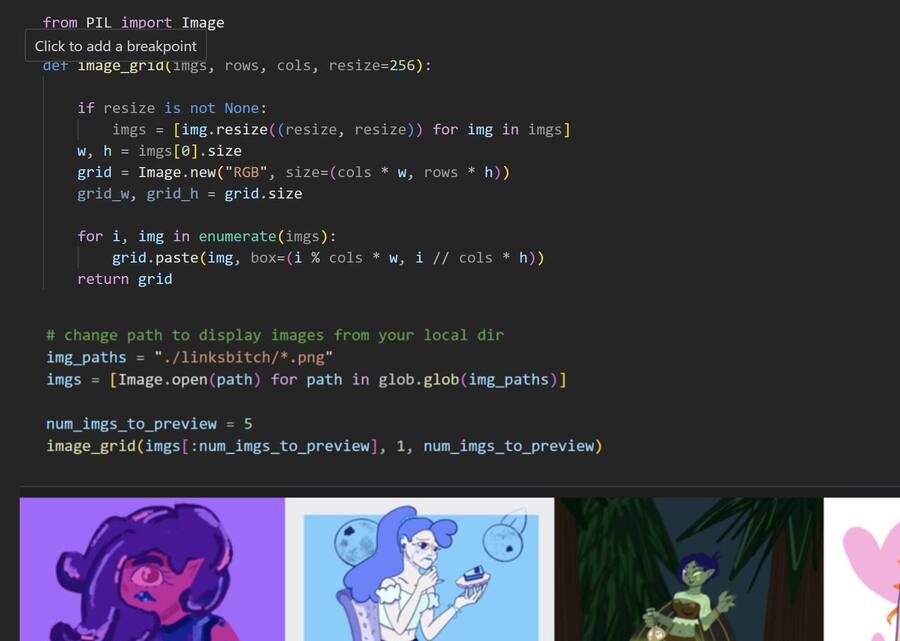
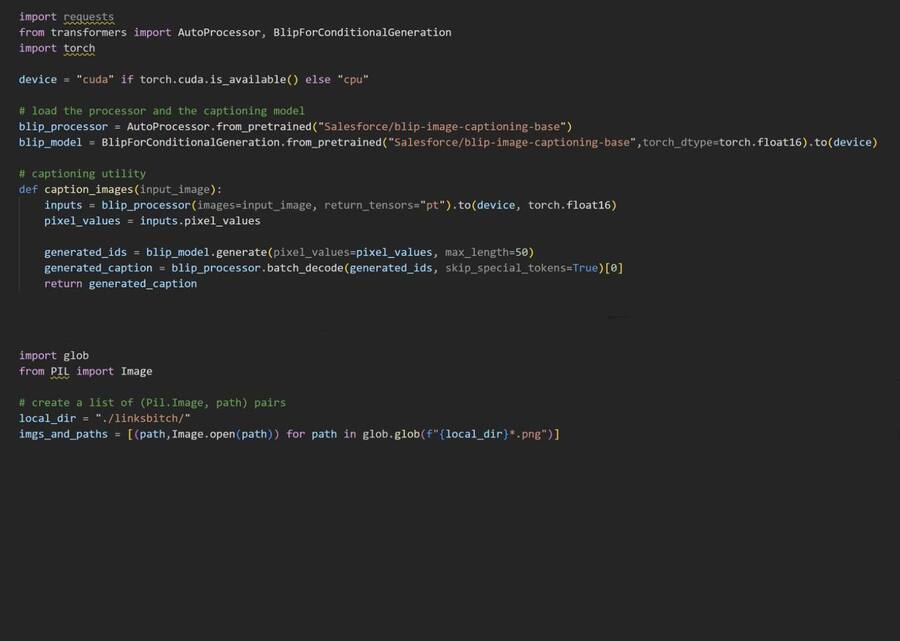
Затем занялась подготовкой данных. Создала директорию для хранения изображений. Загрузила изображения.
Скриншот из Google Collab
Отобразила первые 5 изображений.
Затем загрузила модель BLIP (Bootstrapped Language-Image Pretraining) для генерации текстовых описаний изображений. Создала функцию, которая принимает изображение и возвращает его описание.
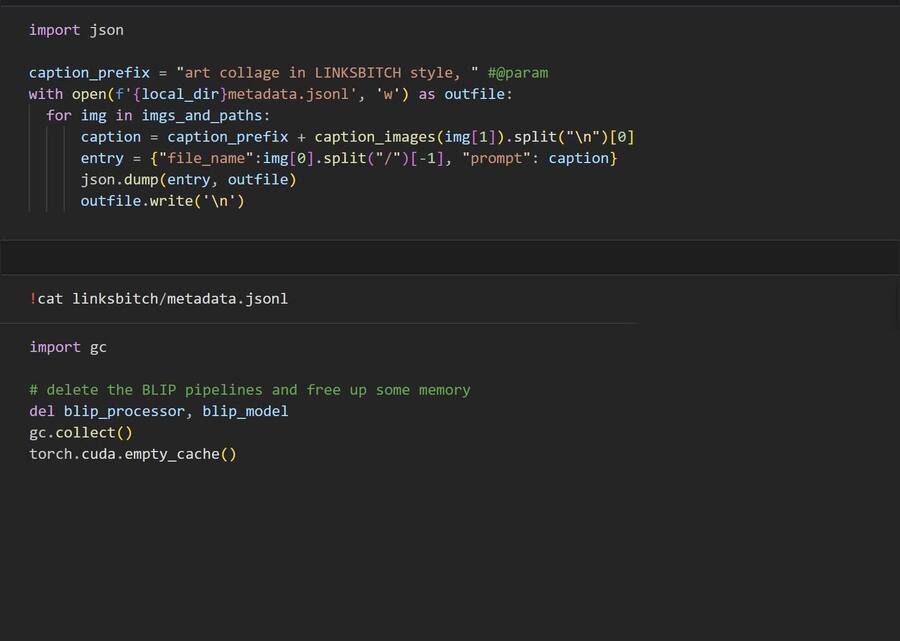
Далее добавила префикс к описаниям, чтобы указать стиль, затем создала файл метаданных в формате JSONL.
Затем удалила модель BLIP т. к. она больше не нужна, чтобы оптимизировать память GPU.
Скриншот из Google Collab
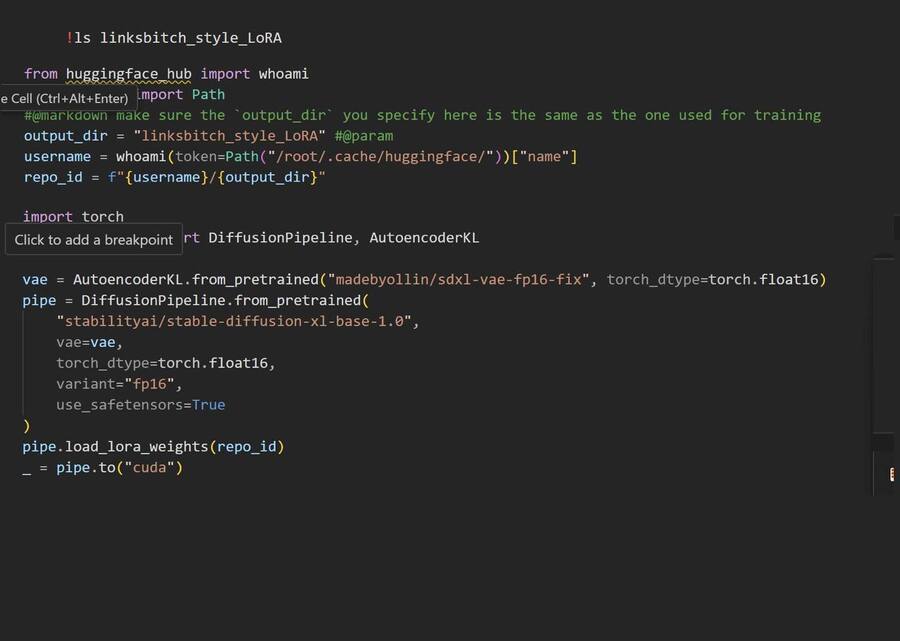
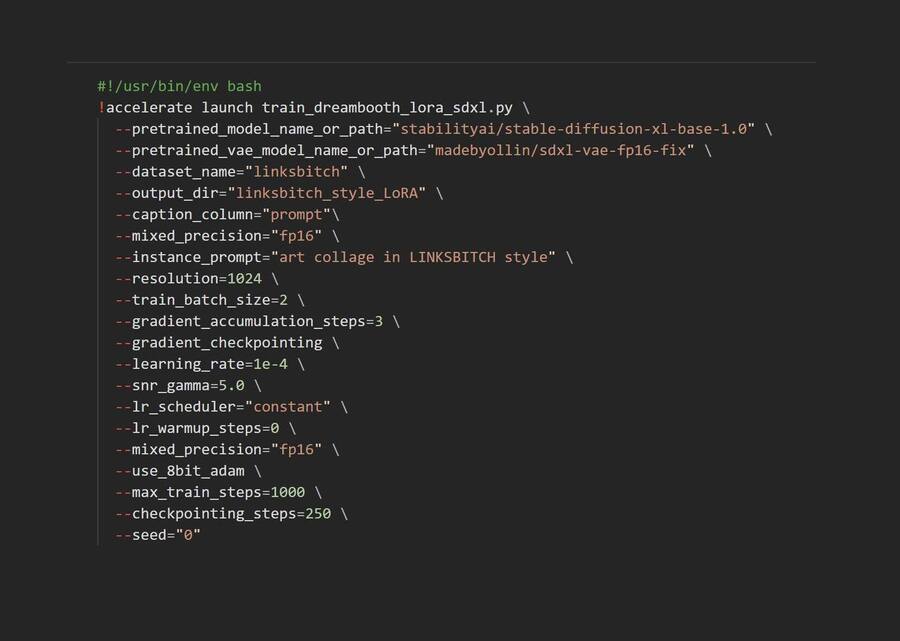
Настроила кодировку и конфигурировала асcelerate для распределенного обучения. Затем мне нужно было авторизироваться в Hugging Face Hub.
Запустила обучение.
Создала репозиторий Hugging Face Hub и сохранила карточку с информацией об обучении. Затем загрузила все модели уже в сам репозиторий. Ну и дело осталось за сладким.
Скриншот из Google Collab
Приступила к генерации картинок.
Применения генеративной модели
Stable Diffusion — обучение модели для генерации изображений в стиле моих рисунков.
BLIP — генерация промптов к исходным компонентам датасета.
Библиотека с моими рисунками по которым училась нейросеть.