
Тренды в киноиндустрии
Концепция
Я решил изучить тренды в киноиндустрии, чтобы понять, как меняются предпочтения зрителей, какие жанры становятся популярнее, и как бюджет фильма влияет на его успех.
Кино — это не только искусство, но и огромная индустрия, которая влияет на культуру и экономику. Мне было интересно узнать, какие закономерности можно выявить в данных о фильмах, и как эти знания могут помочь в создании успешных проектов.

Мне было интересно проанализировать данные о фильмах, потому что кино — это не только искусство, но и важная часть современной культуры и экономики. Этот датасет содержит информацию о бюджетах, кассовых сборах, жанрах, рейтингах и датах выпуска фильмов, что позволяет изучить множество аспектов киноиндустрии.
Для визуализации данных я использовал несколько видов графиков, каждый из которых решал конкретную задачу. Линейный график показывает, как меняется популярность жанров с течением времени. Столбчатые диаграммы я выбрал для сравнения средних кассовых сборов по жанрам. Круговая диаграмма помогла показать распределение фильмов по жанрам. Гистограмма позволила проанализировать распределение рейтингов.

Для анализа я использовал датасет The Movies Dataset который нашёл на платформе Kaggle. Этот датасет содержит информацию о 45 000 фильмов, включая: бюджет и кассовые сборы, жанры, рейтинги, даты выпуска.
Он достаточно объёмный и содержит разнообразные данные, которые позволяют провести глубокий анализ. Кроме того, данные хорошо структурированы, что упрощает их обработку.
Обработка данных
Я начал с загрузки данных в Google Colab. Для этого я использовал библиотеку Pandas.
Для загрузки данных я использовал функцию files.upload () из библиотеки Google Colab, которая позволяет загрузить файл с компьютера. Затем я прочитал данные с помощью функции pd.read_csv (), чтобы загрузить их в DataFrame. Это позволило мне начать работу с данными.
После загрузки я проверил данные на наличие пропусков и ошибок. Например, некоторые строки не содержали информации о бюджете или жанрах, поэтому я удалил их, чтобы не искажать результаты анализа.
Я удалил строки с пропущенными значениями с помощью функции dropna (), чтобы избежать ошибок в анализе. Затем я преобразовал столбцы budget и revenue в числовой формат с помощью astype (float), чтобы можно было выполнять математические операции. Также я добавил новый столбец year, извлекая год из даты выпуска фильма с помощью pd.to_datetime ().dt.year.
Одной из ключевых задач было преобразование столбца с жанрами. В исходном датасете жанры были записаны в формате JSON, что затрудняло их анализ. Я преобразовал этот столбец в список, чтобы можно было легко работать с каждым жанром отдельно.
Для преобразования столбца genres я использовал функцию ast.literal_eval (), которая преобразует строку в формате JSON в список словарей. Затем я извлёк названия жанров с помощью спискового включения [i['name'] for i in …] и применил это ко всем строкам с помощью apply ().
Линейный график
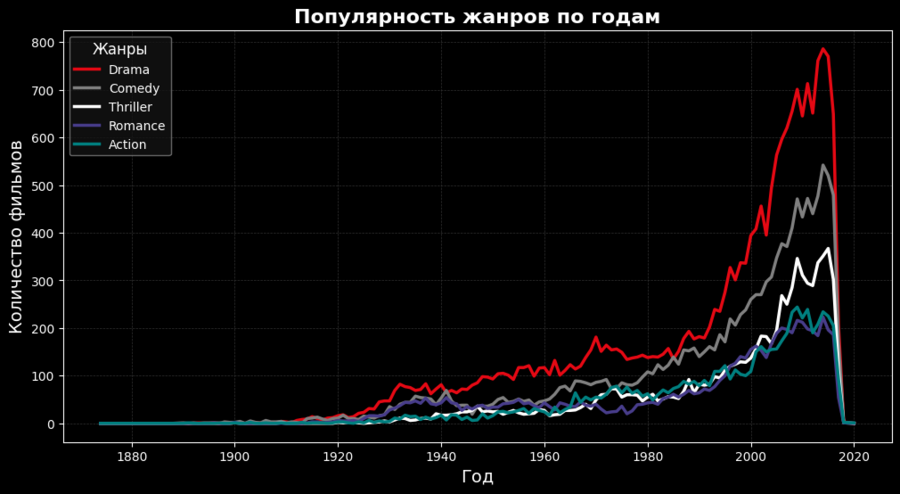
Этот график показывает, как менялась популярность различных жанров с течением времени. Например, можно заметить, что жанры «драма» и «комедия» популярнее чем боевик.
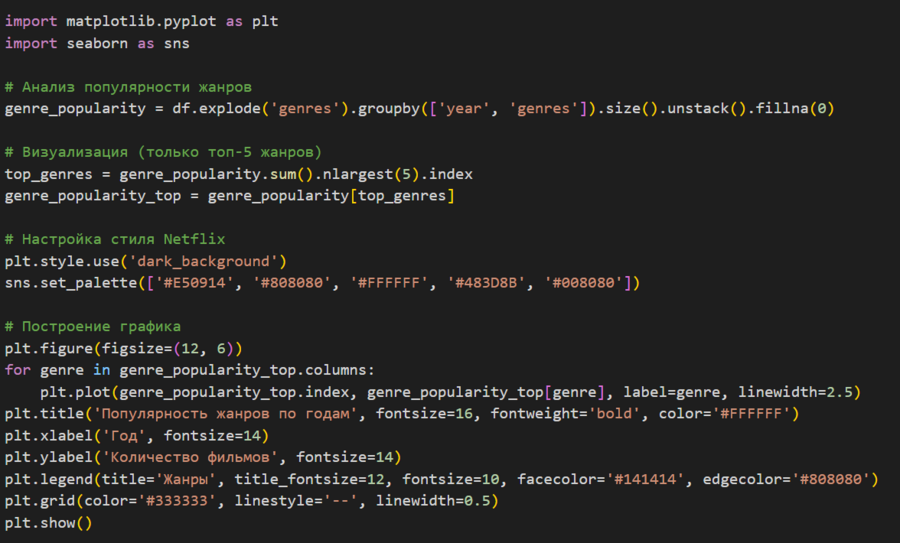
Для анализа популярности жанров я использовал функцию explode (), которая разделяет строки с несколькими жанрами на отдельные строки. Затем я сгруппировал данные по году и жанру с помощью groupby () и создал таблицу, где строки — годы, а столбцы — жанры. Для визуализации я использовал sns.lineplot (), чтобы построить линейный график для каждого жанра. Также я настроил цветовую палитру с помощью sns.set_palette () и установил тёмный фон с помощью plt.style.use ('dark_background').
Столбчатая диаграмма
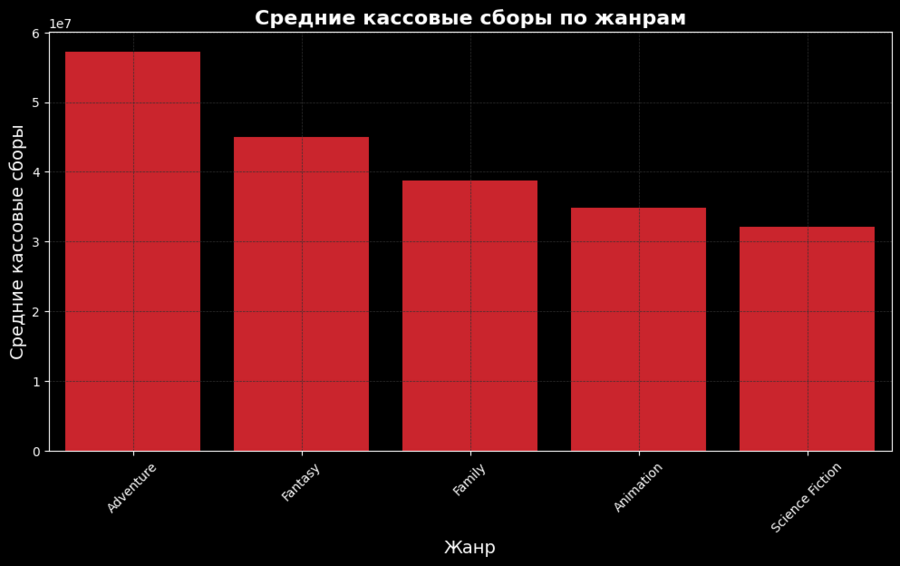
Столбчатая диаграмма позволяет сравнить средние кассовые сборы фильмов разных жанров. Видно, что фильмы в жанре «фантастика» и «приключения» чаще всего собирают больше денег в прокате.
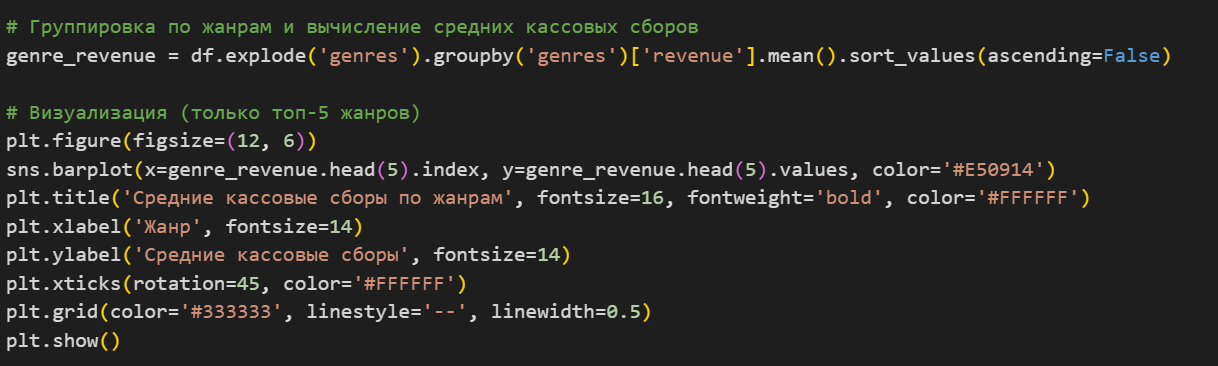
Для анализа кассовых сборов я сгруппировал данные по жанрам с помощью groupby () и вычислил средние значения с помощью mean (). Затем я отсортировал результаты по убыванию с помощью sort_values (). Для визуализации я использовал sns.barplot (), чтобы построить столбчатую диаграмму. Чтобы подписи на оси X не накладывались друг на друга, я повернул их на 45 градусов с помощью plt.xticks (rotation=45).
Круговая диаграмма
Круговая диаграмма показывает, какие жанры наиболее представлены в датасете. Например, драмы и комедии составляют значительную часть всех фильмов.
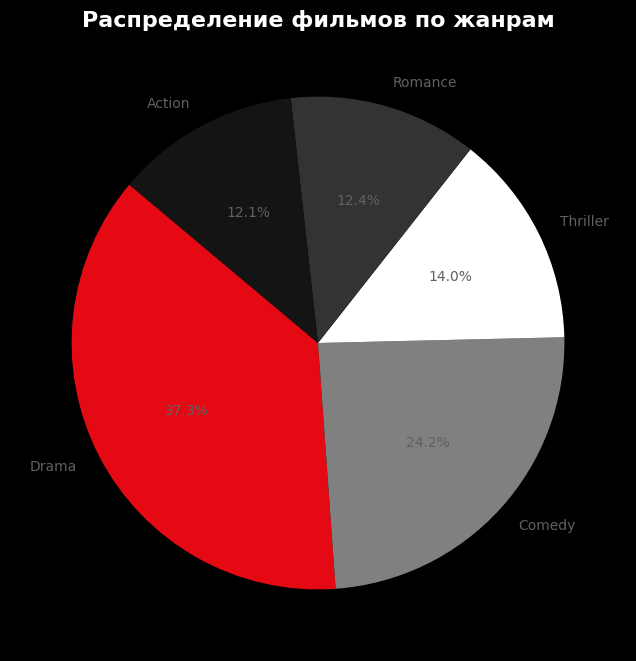
Для анализа распределения фильмов по жанрам я использовал функцию value_counts (), которая подсчитывает количество фильмов для каждого жанра. Затем я построил круговую диаграмму с помощью plt.pie (), добавив проценты с помощью autopct='%1.1f%%'.
Гистограмма
Гистограмма демонстрирует, как распределены рейтинги фильмов. Большинство фильмов имеют рейтинг от 6 до 8 баллов, что говорит о том, как зрители оценивают фильмы.
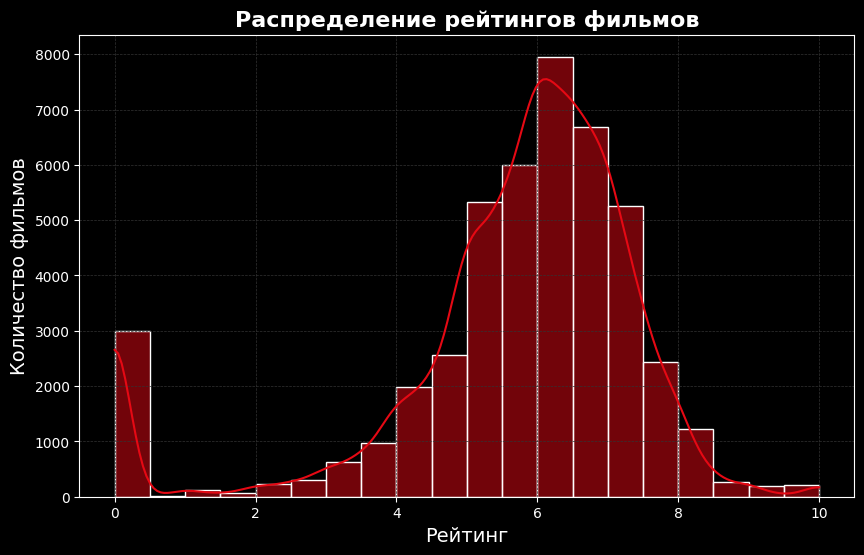
Для анализа распределения рейтингов я использовал sns.histplot (), чтобы построить гистограмму. Я добавил кривую плотности с помощью kde=True, чтобы сделать график более наглядным.
Список источников
Работа с Pandas: Функция read_csv() Пропущенные значения Группировка данных Преобразование JSON в Pandas: Преобразование JSON в список Стилизация графиков: Настройка стилей графиков Обработка текстовых данных: Текстовые данные
Визуализация данных: Линейные графики Столбчатые диаграммы Круговые диаграммы Гистограммы