
Создание стилизованных графиков по датасету
РУБРИКАТОР
1. Вводная часть 2. Обработка данных 3. Стилизация графиков 4. Графики 5. Описание применения генеративной модели 6. Ссылки 7. Источники информации
ВВОДНАЯ ЧАСТЬ
Для работы я выбрала датасет Coffee Taste Test из открытых данных сайта Kaggle.
Я выбрала этот датасет, потому что очень люблю кофе и обязательно выпиваю как минимум одну чашку каждый день. Мне стало интересно проанализировать какие-нибудь данные, связанные с кофе.
В своей работе я использовала четыре вида графиков: круговая диаграмма, столбчатая диаграмма, горизонтальная столбчатая диаграмма и коробочная диаграмма. Я подумала, что эти четыре больше всего подходят для стилизации под кофейную тему, поскольку круговая напоминает вид сверху на чашку, столбчатая — вид сбоку, горизонтальная — стол, а коробочная навивает мысли о коробках для кофе.
ОБРАБОТКА ДАННЫХ
Процесс обработки данных начался с подключения необходимых библиотек: pandas, matplotlib.pyplot, seaborn, numpy. Затем, я добавила датасет и вырезала из него только те колонки, которые буду анализировать.

Список колонок из таблицы, которые понадобятся
Дальше я прошлась по всем выбранным колонкам и посчитала сколько пропусков в каждой колонке.
Выявление пустых ячеек
Получив результат подсчета, я сформировала гипотезу: в данных есть люди, про которых мало что известно, и большинство пропусков относятся к ним. Чтобы ее проверить я посчитала количество людей с пропусками.
Количество людей с пропусками в данных
Оказалось, что строк с пропусками примерно 13% от общего числа. Я решила убрать проблемные строчки, поскольку еще останется 87% данных, по которым будет удобнее строить графики.
Убираем пустые строки
Далее я убрала лишние данные в строке «Пол», оставив только «Male» и «Female», а остальные объединила под названием «Other».
Обработка данных колонки «Пол»
После этого я приступила к построению графиков по данным. Сначала я анализировала где и по какой причине люди пьют кофе. Результат представлялся в виде круговых диаграмм.
Выявление места и причины для питья кофе
Следующий график отражает любимые напитки и топпинги. Результат представлялся в виде столбчатых диаграмм.
Любимые напитки и топпинги
Следующая диаграмма отражает сколько чашек кофе пьют люди разных возрастов. Ширина полосы показывает процент людей по количеству чашек из 100%. Результат представлялся в виде горизонтальных диаграмм.
Чашки кофе на возраст
После нее созданы подобные диаграммы с анализом предпочтений по крепости и прожарке среди людей разных возрастов.


Крепкость / Прожарка
Последние четыре диаграммы посвящены оценке четырех кофейных напитков у групп разных возрастов и с показателями по полу. Результат представлялся в виде коробочных диаграмм.
Оценка напитков 1
Оценка напитков 2
Оценка напитков 3
Оценка напитков 4
СТИЛИЗАЦИЯ ГРАФИКОВ
У меня не было конкретного референса для стилизации, я хотела придумать ее сама. Поэтому нашла только названия цвето, создала график-палитру с оттенками кофейных напитков и использовала эти цвета для окрашивания диаграмм. Также я прочитала, что можно создать паттерны из знаков ’’-’’, ’’/’’, ’’.’’, ’’*’’ и ’’||’’, поэтому некоторые графики дополнила паттернами.
Цветовая палитра
ГРАФИКИ
В данном случае, круговые диаграммы наилучшим образом показывают отношение наиболее популярных ответов.
Можно заметить, что самое популярное место — дома, а причина — он вкусный.
Круговые диаграммы: где люди пьют кофе и почему
Здесь больше категорий, поэтому нагляднее показать их столбчатой диаграммой.
Мы видим, что самые популярные типы напитков — пуровер (особый метод заваривания) и латте, а менее популярные — взбитый (как фраппе) и колд-брю.
Среди топпингов лидирует показатель кофе без топпинга (просто черный), а самый низкий у других вариантов, не вошедших в большие категории. Одинаковые показатели у молока, растительного молока и сливок.
Столбчатые диаграммы: любимые типы напитков и топпингов
Данные по возрастным группам было удобнее оформлять горизонтальными диаграммами, на которых видно процентное соотношения показателя (чашек кофе / крепкость / прожарка) по группе.
Количество чашек кофе на людей разных возрастов
Предпочтения по крепости кофе
Предпочтения по обжарке
Данные с результатами предпочтений после дегустации удобно показывать с помощью коробочных диаграмм. Они удачно презентуют распределение значений колонки, когда нужно сравнить несколько показателей (в данном случае: возраст, пол и результаты опроса).
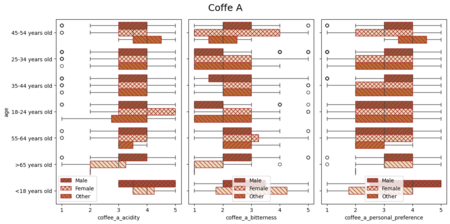
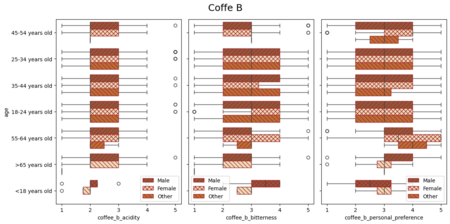
Отзывы о напитках
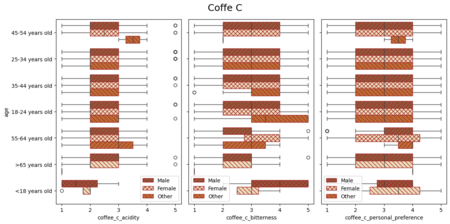
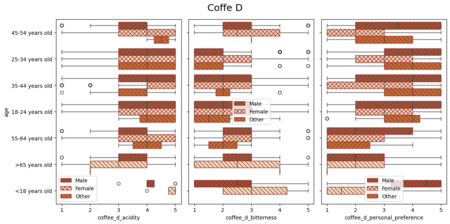
Отзывы о напитках
ОПИСАНИЕ ПРИМЕНЕНИЯ ГЕНЕРАТИВНОЙ МОДЕЛИ
При создании графиков не использовались нейросети. Единственный элемент проекта, созданный с помощью нейросети — обложка. Она создана в нейросети Кандинский (Fusion Brain) по промту: «три прозрачные чашки с латте, капучино и сладким кофе стоят на столе рядом друг с другом, фон размытый с гирляндой».
ССЫЛКИ
ИСТОЧНИКИ
1. Датасет — Kaggle: https://www.kaggle.com/datasets/joebeachcapital/coffee-taste-test 2. Обложка — Fusion Brain: https://fusionbrain.ai/